最近面试经常碰到数据库的基础问题,今天就来总结下!
查询
简单查询的三种情况
1 | select id from user |
1 | select id , real_name from user |
1 | select * from user |
利用distinct关键字去重(查询不同的行,比如id一样的出现多次只取一个)
1 | select distinct id from user |
限制结果
1 | select * from user limit 1,100 |
第一个参数代表偏移量(从0开始,比如上面的1已经代表的是第二条数据了),第二个代表条数。
排序
1 | select real_name from user order by id |
默认是升序排序(从小到到,从a到z)
其实上面也等于
1 | select real_name from user order by id asc |
降序排序
1 | select real_name from user order by id desc |
desc代表使用降序排序
按多个列排序
1 | select * from user order by real_name ,id |
先按第一个排序,如果第一参数一样,再按第二个参数来排序
小扩展:如何寻找一个列中的最高值或者最低值
如下查询了手机号码最小的数据
1 | select * from user order by phone limit 1 |
where条件查询
1 | select * from user where id = 1001 |
1 | select * from user where id > 1001 |
1 | select * from user where id >= 1001 |
1 | select * from user where id < 1001 |
1 | select * from user where id <= 1001 |
不等于
1 | select * from user where id <> 1001 |
1 | select * from user where id != 1001 |
1001-1003范围内的数据
1 | select * from user where id between 1001 and 1003 |
空值检查
1 | select * from user where nick_name is null |
and
1 | select * from user where real_name = '郭秋景' and gender = 1 |
or
1 | select * from user where real_name = '郭秋景' or id = 1200 |
in
1 | select * from user where id in (1002,1003) |
1 | select * from user where id |
not
where 字句中的not操作符有且只有一个功能,就是否定它之后所跟的条件
1 | select * from user where id not in (1002,1003) |
like匹配查询
通配符
%表示任何字符出现任意次数
1 | select * from user where id like '11%' |
11后面不管有多少位,都要
1 | select * from user where id like '11_' |
11后面只能有一位,多位不要!
尾空格问题:尾空格会干扰通配符,假设保存词11时,如果它后面有一个或多个空格,则字句where id like ‘%11’ 将不会匹配他们,因为在最后的1后有多余的字符。
解决方法:搜索条件最后附加一个%;保存时候去掉首尾空格。
NULL不能匹配。
concat拼接
1 | select concat(id,'-',real_name) from user where id =1000 |
使用别名
1 | select concat(id,'-',real_name) as code from user where id =1000 |
算术运算
1 | select prod_id , quantity , item_price , quantity * item_price |
函数
文本处理函数
trim,rtrim,ltrim
upper:将文本转换为大写
日期和时间处理函数
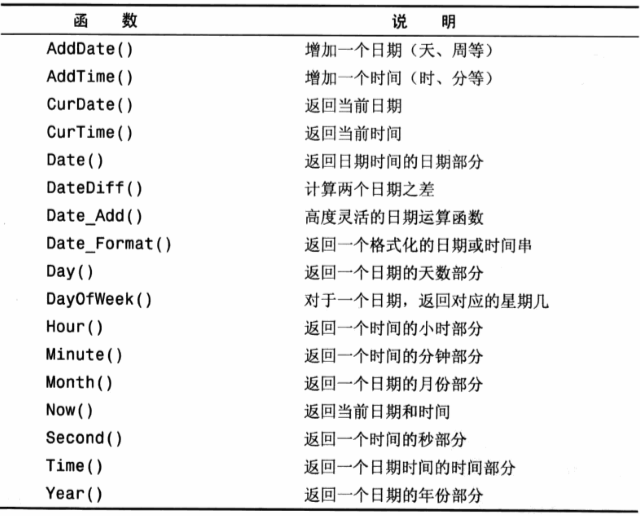
看到这么多好的函数,就直接用了一个过来查询试试啦。
下面这个是查询创建时间已经超过7天的数据
1 | SELECT id,open_id,create_time ,DATEDIFF(NOW(),create_time) as out_time from wechat_form where DATEDIFF(NOW(),create_time) >=7 |
下面这个是删除超过30天的数据
1 | delete from wechat_form where DATEDIFF(NOW(),create_time) >=30 |
删库跑路了。。。
数值处理函数
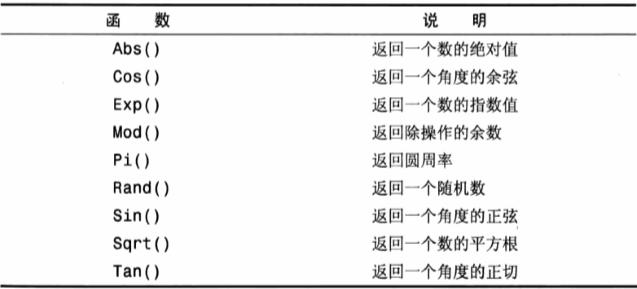
聚集函数

1 | select avg(prod_price) as avg_price from products |
count()函数进行计数,可利用 count() 确定表中行的数目或符合特定条件的行的数目。
count(*):对表中行的数目进行计数,不管表列中包含的是空值还是非空值。
count(column):对特定列中具有值的行进行计数,不包括空值。
max()函数返回指定列中的最大值。max()要求指定列名。
min()函数返回指定列中的最小值。min()要求指定列名。
sum()函数用来返回指定列值的和(总计)
1 | select sum(quantity) as items_ordered from orderitems where order_num = 20005 |
sum()函数也支持算术运算
1 | select sum(quantity * items_price) as total_price from orderitems where order_num = 2005 |
分组数据
group by
1 | select activity_id , count(*) from entry group by activity_id |
联结
inner join
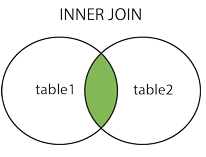
1 | select a.* from activity as a inner join entry as e on a.id = e.activity_id |
inner 也可以省略
1 | select a.* from activity as a join entry as e on a.id = e.activity_id |
等价于 where
left join
左连结:会读取左边数据表的所有选取的字段数据,即便在右侧表无对应数据。
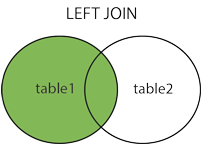
1 | select a.* from activity as a left join entry as e on a.id = e.activity_id |
right join
右连结:会读取右边数据表的全部数据,即便左边边表无对应数据。
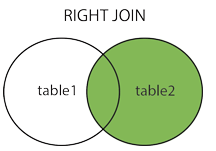
1 | select a.* from activity as a right join entry as e on a.id = e.activity_id |
更新数据
更新一个字段
1 | update user set nick_name = '123456' where id = 1000 |
更新多个字段
1 | update user set nick_name = '123456' , gender = 1 where id = 1000 |
删除数据
按条件删除
1 | delete from user where id = 1000 |
删除所有
1 | delete from user |
注意:删除语句没有*
插入数据
插入完整的行
1 | insert into user values(1001,'郭秋景','18') |
对每个列必须提供一个值,如果没有值,应该使用NULL
插入行的一部分
1 | insert into user (id,name,age) values(1001,'郭秋景',18) |
表名后的括号里明确指出了列名,在插入行时,mysql将values列表中的相应值填入列表中的对应项。
优点:即使表结构发生改变,依然可以工作。
插入多行
1 | insert into user (id,name,age) values(1001,'郭秋景',18),values(1002,'帝创',18) |
每组值用括号括起来,用逗号分隔
插入某些查询的结果
1 | insert into resource (name,url) select name,url from resource |
锁
分类
按照锁的粒度分类
Mysql为了解决并发、数据安全的问题,使用了锁机制。
可以按照锁的粒度把数据库锁分为表级锁和行级锁。
表级锁
Mysql中锁定 粒度最大 的一种锁,对当前操作的整张表加锁,实现简单 ,资源消耗也比较少,加锁快,不会出现死锁 。其锁定粒度最大,触发锁冲突的概率最高,并发度最低,MyISAM和 InnoDB引擎都支持表级锁。
行级锁
Mysql中锁定 粒度最小 的一种锁,只针对当前操作的行进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。 InnoDB支持的行级锁,包括如下几种。
- Record Lock: 对索引项加锁,锁定符合条件的行。其他事务不能修改和删除加锁项;
- Gap Lock: 对索引项之间的“间隙”加锁,锁定记录的范围(对第一条记录前的间隙或最后一条将记录后的间隙加锁),不包含索引项本身。其他事务不能在锁范围内插入数据,这样就防止了别的事务新增幻影行。
- Next-key Lock: 锁定索引项本身和索引范围。即Record Lock和Gap Lock的结合。可解决幻读问题。
虽然使用行级索具有粒度小、并发度高等特点,但是表级锁有时候也是非常必要的:
- 事务更新大表中的大部分数据直接使用表级锁效率更高;
- 事务比较复杂,使用行级索很可能引起死锁导致回滚。
按照是否可写分类
表级锁和行级锁可以进一步划分为共享锁(s)和排他锁(X)。
共享锁(s)
共享锁(Share Locks,简记为S)又被称为读锁,其他用户可以并发读取数据,但任何事务都不能获取数据上的排他锁,直到已释放所有共享锁。
共享锁(S锁)又称为读锁,若事务T对数据对象A加上S锁,则事务T只能读A;其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这就保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
排他锁(X):
排它锁((Exclusive lock,简记为X锁))又称为写锁,若事务T对数据对象A加上X锁,则只允许T读取和修改A,其它任何事务都不能再对A加任何类型的锁,直到T释放A上的锁。它防止任何其它事务获取资源上的锁,直到在事务的末尾将资源上的原始锁释放为止。在更新操作(INSERT、UPDATE 或 DELETE)过程中始终应用排它锁。
两者之间的区别:
- 共享锁(S锁):如果事务T对数据A加上共享锁后,则其他事务只能对A再加共享锁,不 能加排他锁。获取共享锁的事务只能读数据,不能修改数据。
- 排他锁(X锁):如果事务T对数据A加上排他锁后,则其他事务不能再对A加任任何类型的封锁。获取排他锁的事务既能读数据,又能修改数据。
另外两个表级锁:IS和IX
当一个事务需要给自己需要的某个资源加锁的时候,如果遇到一个共享锁正锁定着自己需要的资源的时候,自己可以再加一个共享锁,不过不能加排他锁。但是,如果遇到自己需要锁定的资源已经被一个排他锁占有之后,则只能等待该锁定释放资源之后自己才能获取锁定资源并添加自己的锁定。而意向锁的作用就是当一个事务在需要获取资源锁定的时候,如果遇到自己需要的资源已经被排他锁占用的时候,该事务可以需要锁定行的表上面添加一个合适的意向锁。如果自己需要一个共享锁,那么就在表上面添加一个意向共享锁。而如果自己需要的是某行(或者某些行)上面添加一个排他锁的话,则先在表上面添加一个意向排他锁。意向共享锁可以同时并存多个,但是意向排他锁同时只能有一个存在。
InnoDB另外的两个表级锁:
- 意向共享锁(IS): 表示事务准备给数据行记入共享锁,事务在一个数据行加共享锁前必须先取得该表的IS锁。
- 意向排他锁(IX): 表示事务准备给数据行加入排他锁,事务在一个数据行加排他锁前必须先取得该表的IX锁。
注意:
- 这里的意向锁是表级锁,表示的是一种意向,仅仅表示事务正在读或写某一行记录,在真正加行锁时才会判断是否冲突。意向锁是InnoDB自动加的,不需要用户干预。
- IX,IS是表级锁,不会和行级的X,S锁发生冲突,只会和表级的X,S发生冲突。
InnoDB的锁机制兼容情况如下:
当一个事务请求的锁模式与当前的锁兼容,InnoDB就将请求的锁授予该事务;反之如果请求不兼容,则该事物就等待锁释放。
死锁和避免死锁
InnoDB的行级锁是基于索引实现的,如果查询语句为命中任何索引,那么InnoDB会使用表级锁. 此外,InnoDB的行级锁是针对索引加的锁,不针对数据记录,因此即使访问不同行的记录,如果使用了相同的索引键仍然会出现锁冲突,还需要注意的是,在通过
1 | SELECT ...LOCK IN SHARE MODE;1 |
或
1 | SELECT ...FOR UPDATE;1 |
使用锁的时候,如果表没有定义任何索引,那么InnoDB会创建一个隐藏的聚簇索引并使用这个索引来加记录锁。
此外,不同于MyISAM总是一次性获得所需的全部锁,InnoDB的锁是逐步获得的,当两个事务都需要获得对方持有的锁,导致双方都在等待,这就产生了死锁。 发生死锁后,InnoDB一般都可以检测到,并使一个事务释放锁回退,另一个则可以获取锁完成事务,我们可以采取以上方式避免死锁:
- 通过表级锁来减少死锁产生的概率;
- 多个程序尽量约定以相同的顺序访问表(这也是解决并发理论中哲学家就餐问题的一种思路);
- 同一个事务尽可能做到一次锁定所需要的所有资源。
总结与补充
MyISAM和InnoDB存储引擎使用的锁:
- MyISAM采用表级锁(table-level locking)。
- InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁
表级锁和行级锁对比:
- 表级锁: Mysql中锁定 粒度最大 的一种锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。其锁定粒度最大,触发锁冲突的概率最高,并发度最低,MyISAM和 InnoDB引擎都支持表级锁。
- 行级锁: Mysql中锁定 粒度最小 的一种锁,只针对当前操作的行进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。
补充:
页级锁: MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。页级进行了折衷,一次锁定相邻的一组记录。BDB支持页级锁。开销和加锁时间界于表锁和行锁之间,会出现死锁。锁定粒度界于表锁和行锁之间,并发度一般。